
Architettura del software: le applicazioni web a tre livelli
Quando si progettano e realizzano applicazioni data-centric, ovvero applicazioni che sfruttano una sorgente dati (nel caso piů comune, un database relazionale) per persistere le informazioni trattate, l'approccio piů diffuso, specialmente nel caso di applicazioni complesse, č quello di scomporre il sistema in diversi strati applicativi (layer), ciascuno dei quali caratterizzato da una forte focalizzazione e specializzazione funzionale. Ogni livello assolve compiti specifici e omogenei, č in grado di comunicare con gli altri layer e demanda ad essi le eventuali azioni non di propria pertinenza. Tra i diversi strati esiste una certa gerarchia, nel senso che il rapporto tra i layer in generale non č paritetico, ma č regolato da un insieme di dipendenze che permettono di individuare un ordine di relazione. Questo significa che ogni livello "si appoggia" ad uno o piů strati per poter eseguire i suoi compiti, dipende da essi e comunica unicamente con loro.
Architetture a tre livelli
Nelle applicazioni data-centric il processo di scomposizione a cui si č accennato permette di individuare almeno tre livelli logici principali. Per questo motivo, quando ci si riferisce a questo tipo di applicazioni, si parla in generale di architetture a tre livelli (figura 1). Questo non toglie che in taluni casi possano esistere piů layer, peraltro lo stile architetturale piů diffuso ne prevede principalmente tre. I layer in questione sono i seguenti:
- User Interface (UI o strato di presentazione): ha lo scopo di gestire l'interazione del sistema con il mondo esterno, in particolare con gli utenti. Include le maschere per la visualizzazione e l'inserimento dei dati, i controlli, dai piů semplici ai piů complessi, e i meccanismi per intercettare e trattare opportunamente gli eventi che sono scatenati in funzione delle azioni svolte dagli utenti;
- Business Logic Layer (BLL o logica di business): include l'insieme delle regole di business che regolano il funzionamento dell'applicazione, intercetta le richieste provenienti dallo strato di presentazione e le gestisce opportunamente;
- Data Access Layer (DAL o strato di accesso ai dati): si occupa di persistere le informazioni trattate dall'applicazione e conosce le modalitŕ per leggerle e salvarle nell'ambito di una sorgente dati (non necessariamente un database relazionale).
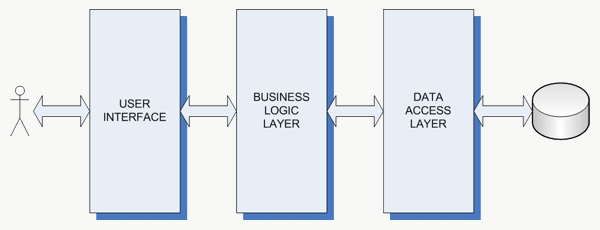
Figura 1: architettura a tre livelli.
I vantaggi nella scelta di una architettura a livelli sono numerosi. L'approccio basato su layer consente di limitare l'accoppiamento e le duplicazioni funzionali, promuovendo la creazione di oggetti fortemente specializzati e coesi. La distribuzione delle responsabilitŕ applicative su piů oggetti implica che le funzionalitŕ piů complesse vengono in generale ottenute dalla collaborazione di piů elementi a minore complessitŕ, il che č un aspetto positivo in quanto un approccio di questo tipo consente di scrivere codice piů robusto.
Se da un lato un numero maggiore di moduli (classi o quant'altro) implica un maggiore sforzo in termini di programmazione, dall'altro la scomposizione dell'applicazione in oggetti raggruppati in modo omogeneo a formare i diversi layer comporta una migliore organizzazione e strutturazione logica del codice, con vantaggi enormi in termini di manutenibilitŕ e scalabilitŕ.
La suddivisione in layer si rivela una soluzione vincente anche in un'ottica di sicurezza applicativa. Suddividendo l'applicazione in piů parti (non solo logiche, ma anche fisiche), č possibile associare a ciascuna di esse le credenziali di sicurezza strettamente necessarie, limitando in questo modo la superficie di attacco e la sensibilitŕ del sistema a vulnerabilitŕ derivanti da bachi interni all'applicazione o legati all'ambiente in cui essa viene eseguita.
Pertanto le architetture a livelli (e, in particolare, quella a tre livelli per le applicazioni data-centric) trovano giustificazione in quegli scenari dove la suddivisione in layer rappresenta un valore aggiunto in termini di gestione del codice e della sua evoluzione nel tempo. Qualora questi aspetti non rappresentino un'esigenza primaria (fermo restando che alcuni elementi come la sicurezza non dovrebbero mai essere degli optional), la scelta di soluzioni architetturali piů semplici e meno strutturate si puň rivelare migliore, se non altro per il semplice fatto che l'ammontare delle attivitŕ di sviluppo in questi casi č inferiore e lo sforzo implementativo č meno impegnativo.
Comunicazione tra layer e rappresentazione delle informazioni
Le applicazioni "hanno il problema" di dover rappresentare in qualche modo le informazioni utilizzate. Ciascuna di queste rappresentazioni fornisce infatti un meccanismo per aggregare i dati relativi alle singole entitŕ appartenenti al dominio reale per rendere agevole il loro utilizzo e lo scambio delle informazioni attraverso i diversi livelli applicativi. Nel caso di applicazioni object-oriented, come possono essere le applicazioni ASP.NET, le entitŕ vengono rappresentate tramite classi, che permettono di raggruppare insieme dati e comportamenti, nonchč di essere relazionate le une con le altre.
Per fare un esempio che si riallaccia a quanto avremo modo di vedere piů avanti nel corso dell'articolo, se si considera un sito e-commerce che vende libri, tra le le entitŕ del mondo reale possiamo individuare i libri, gli ordini e i clienti. Un libro č caratterizzato da un titolo, da uno o piů autori e da una casa editrice, un ordine contiene i dettagli dei libri selezionati da un particolare cliente, e cosě via. Queste entitŕ devono essere necessariamente rappresentate in qualche modo nell'ambito dell'applicazione. Dal momento che ogni entitŕ del mondo reale possiede caratteristiche peculiari, occorre individuare una rappresentazione specifica nei diversi casi.
Un aspetto ulteriore da prendere in considerazione č che la rappresentazione delle entitŕ nell'ambito della sorgente dati generalmente non coincide con quella utilizzata nell'ambito dell'applicazione, in particolar modo se si tratta di un'applicazione che sfrutta il paradigma ad oggetti. Ciascun ambito utilizza infatti un suo modello di rappresentazione. Per esempio, in un database relazionale le informazioni sono organizzate in tabelle, i tipi di dato utilizzati sono per lo piů primitivi, ciascuna riga č identificata da chiavi primarie e le tabelle sono correlate tra loro in base alle chiavi esterne. Nell'ambito di una applicazione object-oriented ogni classe puň invece contenere non solo dati primitivi, ma anche riferimenti ad altre classi. Questo implica che la rappresentazione completa di un oggetto puň dipendere anche dalla rappresentazione degli oggetti ad esso correlati.
Attenzione: Questo articolo contiene un allegato.
Commenti

Per inserire un commento, devi avere un account.
Fai il login e torna a questa pagina, oppure registrati alla nostra community.



 7")