
Gestione della persistenza con NHibernate
Le applicazioni data-driven, cioč quelle che basano gran parte della logica sulla manipolazione di informazioni memorizzate su un database, sono senz'altro tra le piů diffuse. Un approccio sempre piů utilizzato consiste nel modellare i dati sfruttando i vantaggi della programmazione object oriented, secondo il pattern comunemente denominato Domain Model. La gestione della persistenza e del fetch di un grafo di oggetti, a prima vista operazione assolutamente banale, nasconde in realtŕ una serie di insidie che sfociano spesso in complicazioni difficili da superare.
La figura 1, che mostra un semplice modello di dominio di un ipotetico gestionale, rende da sola l'idea di quanto possa essere articolato un grafo di oggetti e come possano essere di conseguenza complesse (oltre che noiose e ripetitive) le operazioni di memorizzazione e lettura dei dati da database.

Figura 1 - Esempio di un grafo delle dipendenze in un modello di dominio
Immaginiamo di dover leggere una fattura da database o di doverne memorizzare una. Operazioni di questo tipo, di per sé estremamente comuni, pongono giŕ i primi dilemmi su quali siano le query da effettuare: dal momento che il grafo č allo stesso tempo complesso e notevolmente interconnesso, quali dati devono essere letti e quali possono essere invece trascurati? A cosa dobbiamo far puntare le reference rimaste vuote? E l'operazione di memorizzazione di una fattura quali entitŕ (e quindi quali tabelle) coinvolge? Si potrebbe continuare a lungo con questi interrogativi, e questo perché il compito di gestire la persistenza di un domain model di questo tipo (tra l'altro volutamente molto semplice) č effettivamente molto complesso.
Un Object/Relational Mapper (O/RM) č un framework che si propone di risolvere problematiche di questo tipo, sostanzialmente generando in maniera intelligente, mirata e soprattutto automatica, query SQL a partire da istruzioni di alto livello impartite dallo sviluppatore. Uno dei prodotti piů diffusi per chi sviluppa in tecnologia .NET č NHibernate (NH), porting di Hibernate del mondo Java, da diversi mesi passato sotto l'egida JBoss (una divisione di Red Hat). Si tratta di un O/RM open source, liberamente scaricabile dal sito www.hibernate.org, dichiarato stabile oramai da alcuni anni e utilizzato con profitto in un gran numero di applicazioni di livello enterprise.
Primi passi con NHibernate
Supponiamo di dover realizzare un'applicazione di fatturazione molto semplice, che lavori con il domain model illustrato in figura 2.
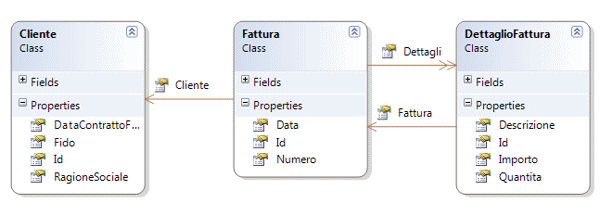
Figura 2 - Modello di dominio
Questo modello corrisponde ad uno schema di tabelle simile a quello rappresentato in figura 3.
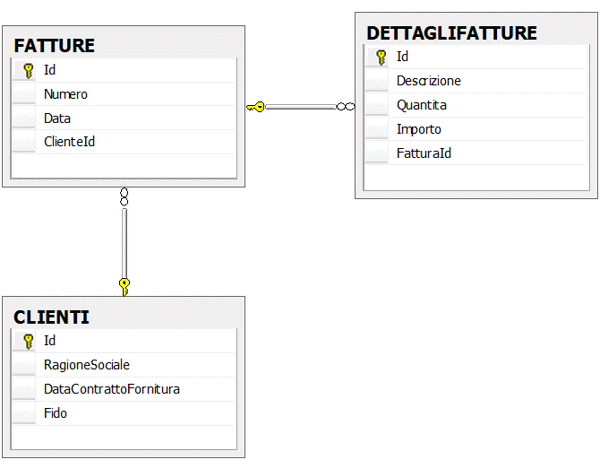
Figura 3 - Schema relazionale
Affinché NHibernate possa generare automaticamente le query SQL per persistere questi oggetti, č necessario creare un file di mapping per ognuno di essi, in cui descriverne la struttura e indicarne la corrispondenza nel database relazionale. Sicuramente la classe Cliente č quella piů facile da cui partire, non possedendo riferimenti verso altre entitŕ di dominio. Il file Cliente.hbm.xml (č questa l'estensione che per convenzione si assegna) contiene qualcosa di simile a quanto riportato di seguito.
<hibernate-mapping xmlns="urn:nhibernate-mapping-2.2" assembly="Aspitalia.Entities" namespace="Aspitalia.Entities" default-lazy="false" default-access="field.camelcase"> <class name="Cliente" table="CLIENTI"> <id name="Id" unsaved-value="0" > <generator class="native" /> </id> <property name="RagioneSociale" /> <property name="DataContrattoFornitura" /> <property name="Fido" /> </class> </hibernate-mapping>
Il contenuto č piuttosto lineare e merita veramente pochi commenti: ad ogni tipo deve corrispondere un nodo <class> tramite il quale associarlo ad una tabella nel mondo relazionale. Dato che ogni riga sul database č univocamente identificata da una chiave primaria, NHibernate ha bisogno di conoscere quale, tra le proprietŕ dell'oggetto, č quella che la rappresenta e, nel caso di una nuova istanza (quando cioé la chiave č pari a quanto indicato come unsaved-value), qual č il generator da utilizzare per calcolarne il valore. Nel nostro caso č stato utilizzato native dato che, su SQL Server, l'identificativo del cliente č contenuto in una colonna identity, ma ne esistono svariati altri, tutti ampiamente descritti nella documentazione ufficiale.
Attenzione: Questo articolo contiene un allegato.
Commenti

Per inserire un commento, devi avere un account.
Fai il login e torna a questa pagina, oppure registrati alla nostra community.
Approfondimenti
Short-circuiting della Pipeline in ASP.NET Core
Implementare il throttling in ASP.NET Core
Load test di ASP.NET Core con k6
Eseguire una query su SQL Azure tramite un workflow di GitHub
Personalizzare l'errore del rate limiting middleware in ASP.NET Core
Effettuare il deploy di immagini solo da container registry approvati in Kubernetes



 7")