
Architettura del software: l'object model per le applicazioni web
Quando si parla di stratificazione e layering di applicazioni web, ci si riferisce a quel tipo di situazioni in cui il dominio complessivo č scomposto in livelli (layer appunto) funzionalmente omogenei organizzati secondo una certa gerarchia e tra essi dipendenti. Ciascun layer condivide con gli altri uno strato comune in cui č presente la rappresentazione del dominio di riferimento. In particolare, nelle applicazioni basate sul paradigma ad oggetti come le applicazioni ASP.NET, il processo di scomposizione porta in genere ad identificare un modello ad oggetti (detto anche Object Model) composto da una serie di classi, la cui connotazione puň dipendere dalle diverse opzioni offerte delle tecnologie esistenti. Ciascuna classe del modello ad oggetti assolve compiti specifici, puň avere responsabilitŕ di fare (ovvero presenta comportamenti espressi sotto forma di metodi), ma soprattutto ha responsabilitŕ di conoscere (ovvero gestisce un suo stato interno tramite campi e proprietŕ). In uno scenario come quello descritto, le funzionalitŕ principali dell'applicazione vengono rese possibili dalla cooperazione delle sue parti costituenti a minore complessitŕ (SoC, Separation of Concerns) e dalle modalitŕ con cui i dati vengono rappresentati e trasmessi attraverso il sistema.
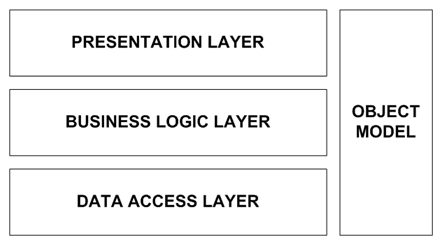
Figura 1 - Modello ad oggetti in un'applicazione a tre livelli
Come detto, l'output del processo menzionato č un modello ad oggetti che descrive il dominio applicativo e chiaramente durante la scomposizione diventa di fondamentale importanza identificare la forma giusta per creare strutture ad oggetti caratterizzate da una buona estendibilitŕ e flessibilitŕ. Ma quali sono i criteri per creare un modello ad oggetti efficiente? Quali sono gli approcci che influenzano il processo di scomposizione? Quali sono le soluzioni migliori?
In realtŕ le soluzioni presenti oggi nel .NET Framework e in ASP.NET per la persistenza dei dati nelle applicazioni web condizionano non poco le scelte di disegno e di implementazione del modello ad oggetti. Molto dipende dall'approccio utilizzato e dalle necessitŕ funzionali richieste dall'applicazione. In questo articolo cercheremo di chiarirci le idee su quali scelte operare nelle diverse situazioni, evidenziando di volta in volta le problematiche esistenti e le possibili alternative.
Due diversi approcci
Se si prende in considerazione una qualsiasi applicazione web, in genere essa utilizza un database relazionale per persistere i dati. La presenza di un database rappresenta pertanto una costante nella maggior parte dei casi. Questa situazione influenza non poco il processo di scomposizione, a tal punto che spesso e volentieri la prima azione svolta nella realizzazione di un'applicazione web č la progettazione dello schema relazionale.
La precedenza data alla stesura del database porta ad una scelta di rappresentazione all'interno delle applicazioni in base alla quale le informazioni trattate vengono lette e usate secondo le stesse logiche di rappresentazione presenti nello strato dati. Questo modo di affrontare la definizione del modello ad oggetti prende il nome di approccio Bottom-Up (traduzione: dal basso verso l'alto). Si tratta di un approccio database-driven, dove la progettazione č focalizzata primariamente sul dominio dei dati (database-first).
Se da un lato tale approccio permette uno start-up piů rapido, magari agevolato dalla presenza di qualche designer utile allo scopo nel tool di sviluppo, dall'altro esso comporta un forte accoppiamento tra il modello ad oggetti applicativo e lo schema relazionale e introduce un certa rigiditŕ di fondo nella struttura ad oggetti a discapito della riusabilitŕ. Per questo motivo l'approccio Bottom-Up si rivela indicato per applicazioni non complesse, dove gli oggetti in gioco sono in numero limitato e in genere il grafo delle relazioni non č particolarmente, per cosě dire, intricato.
L'alternativa all'approccio Bottom-Up č il cosiddetto approccio Top-Down (traduzione: dall'alto verso il basso). In tal caso il processo di scomposizione č influenzato primariamente dai requisiti e dagli aspetti caratteristici del dominio in esame e il modello ad oggetti che ne consegue tende a rappresentare i dati secondo le logiche espresse dai casi d'uso dell'applicazione. La forma di rappresentazione delle informazioni trattate non č influenzata dallo schema relazionale, che perde il suo ruolo centrale e diventa un elemento di progettazione come gli altri.
Il Top-Down č un approccio domain-driven e in tal caso l'object model č per lo piů composto da classi che intendono fornire meccanismi di rappresentazione ed elaborazione fortemente legati al dominio in questione. Il processo di scomposizione produce un insieme di elementi tra loro relazionati secondo le modalitŕ con cui essi vengono usati nell'ambito dell'applicazione. Il focus quindi si sposta dagli aspetti puramente statici (struttura in tabelle e pura rappresentazione) a quelli dinamici e di interazione (casi d'uso, relazioni, logiche di comunicazione). Il basso accoppiamento con lo strato dati permette una maggiore riusabilitŕ e flessibilitŕ dell'object model, con evidenti vantaggi in termini di manutenibilitŕ. A questo aspetto positivo si contrappone peraltro uno start-up meno rapido, la necessitŕ di dover scrivere piů codice e uno scarso supporto di framework e designer automatici. Pertanto questo approccio risulta essere piů indicato in scenari piů complessi, laddove l'investimento iniziale nella definizione dell'object model viene ripagato da una maggior capacitŕ di far evolvere l'applicazione al variare dei casi d'uso e delle specifiche funzionali.
Come rappresentare i dati
Come si č avuto modo di dire giŕ nel paragrafo precedente, il processo di scomposizione viene fortemente condizionato dalla scelta dell'approccio. Se da un lato il Bottom-Up produce una rappresentazione fortemente dipendente dal database, dall'altro il Top-Down permette un alto grado di flessibilitŕ nella definizione del modello ad oggetti. Pertanto la rappresentazione dei dati nei due casi segue forme diverse a seconda del tipo di soluzione adottata.
Parlando di .NET Framework e ASP.NET 3.5, le scelte possibili per rappresentare i dati sono sostanzialmente due:
- container di dati, ovvero classi come i DataSet tipizzati che permettono di contenere anche grandi moli di dati estrapolati da un database e di mantenerli attivi in memoria affinchč possano essere letti e modificati;
- classi custom (entitŕ), generate tramite i designer di Visual Studio (in particolare quelli relativi a LINQ To SQL ed Entity Framework) oppure definite interamente dallo sviluppatore in modo personalizzato (oggetti POCO - Plain Old CLR Objects).
Di seguito vengono trattate le diverse casistiche in relazione alle possibilitŕ offerte dal .NET Framework nella versione 3.5.
Attenzione: Questo articolo contiene un allegato.
Commenti

Per inserire un commento, devi avere un account.
Fai il login e torna a questa pagina, oppure registrati alla nostra community.
Approfondimenti
.NET Conference Italia 2023
Effettuare il deploy di immagini solo da container registry approvati in Kubernetes
Personalizzare l'errore del rate limiting middleware in ASP.NET Core
Le novità di Entity Framework 8
Short-circuiting della Pipeline in ASP.NET Core
Utilizzare HiLo per ottimizzare le insert in un database con Entity Framework
Eseguire una GroupBy per entity in Entity Framework
Utilizzare l'operatore GroupBy come ultima istruzione di una query LINQ in Entity Framework
Implementare il throttling in ASP.NET Core
Load test di ASP.NET Core con k6
Ottimizzare il mapping di liste di tipi semplici con Entity Framework Core



 7")